
Abstract
This paper considers learning robot locomotion and manipulation tasks from expert demonstrations. Generative adversarial imitation learning (GAIL) trains a discriminator that distinguishes expert from agent transitions, and in turn use a reward defined by the discriminator output to optimize a policy generator for the agent. This generative adversarial training approach is very powerful but depends on a delicate balance between the discriminator and the generator training. In high-dimensional problems, the discriminator training may easily overfit or exploit associations with task-irrelevant features for transition classification. A key insight of this work is that performing imitation learning in a suitable latent task space makes the training process stable, even in challenging high-dimensional problems. We use an action encoder-decoder model to obtain a low-dimensional latent action space and train a LAtent Policy using Adversarial imitation Learning (LAPAL). The encoder-decoder model can be trained offline from state-action pairs to obtain a task-agnostic latent action representation or online, simultaneously with the discriminator and generator training, to obtain a task-aware latent action representation. We demonstrate that LAPAL training is stable, with near-monotonic performance improvement, and achieves expert performance in most locomotion and manipulation tasks, while a GAIL baseline converges slower and does not achieve expert performance in high-dimensional environments.
Model

Figure 1. LAPAL overview. We first train action encoder-decoder functions $g_{\omega_1}$, $h_{\omega_2}$ with a conditional variational autoencoder (CVAE) on expert demonstrations $\mathcal{B}_E$ to extract latent action representation. In adversarial imitation learning, we iteratively train a discriminator $D_\phi$ that classifies state and latent action pairs ($\mathbf{s}$, $\bar{\mathbf{a}}$) and train a generator $\bar{\pi}_{\bar{\theta}}$ that predicts latent actions from states. For task-agnostic LAPAL, we update the discriminator and generator parameters $\phi$, $\bar{\theta}$ by formulating a imitation learning objective in the latent space (orange dashed line). For task-aware LAPAL, the action encoder-decoder functions can be jointly optimized with the discriminator and policy (green dashed line).
Results
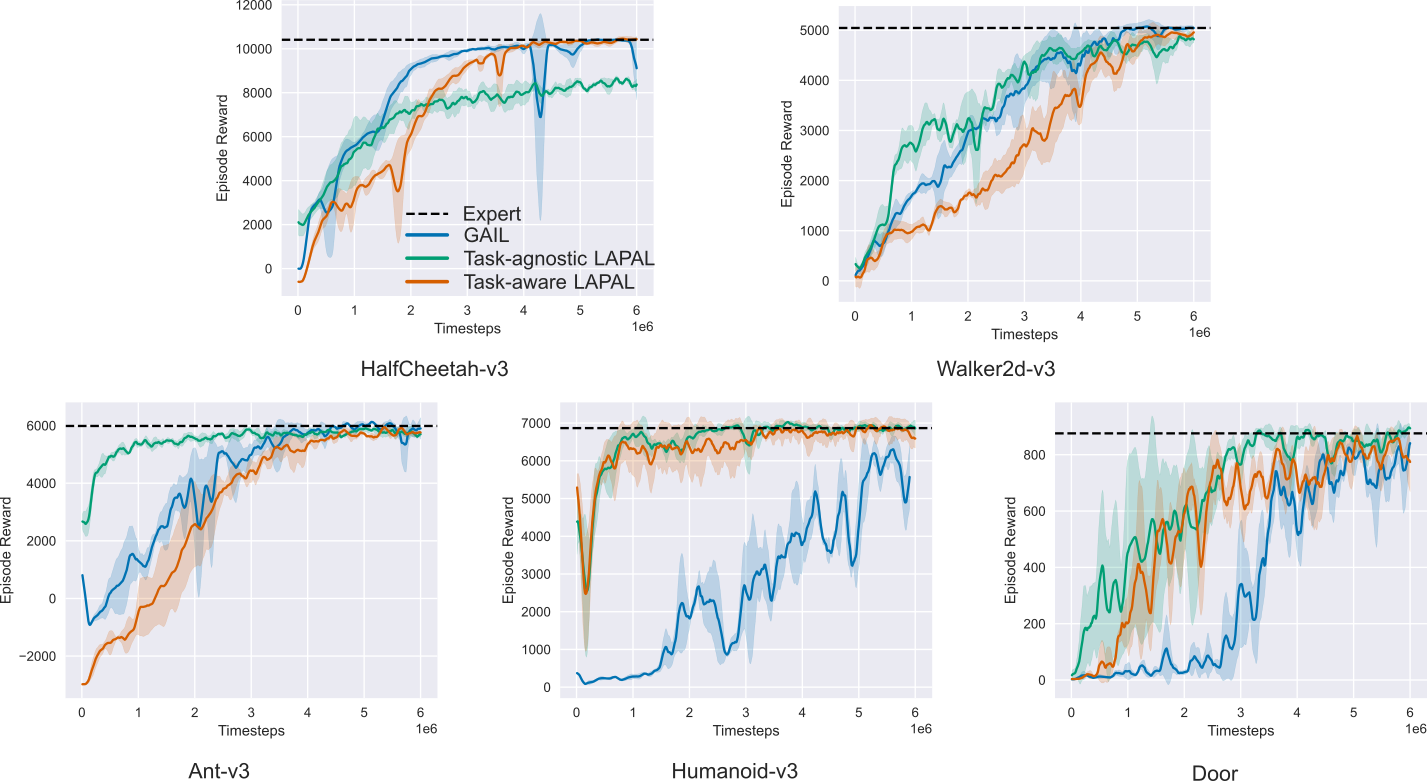
Figure 2. Benchmark results for MuJoCo and robosuite tasks. Each algorithm is averaged over 3 random seeds and the shaded area indicates standard deviation. LAPAL is on par with GAIL in low-dimensional problems such as Walker2d-v3 and HalfCheetah-v3 but converges faster for high-dimensional problems like Ant-v3, Humanoid-v3 and Door. In high-dimensional Humanoid-v3, GAIL fails to recover the optimal policy without addition regularization, e.g. gradient penalty and spectral normalization, while LAPAL converges quickly and asymptotically.
Zero-Shot Transfer Learning with LAPAL


Figure 3. Zero-shot transfer learning for task-agnostic LAPAL from Panda robot (left) to Sawyer robot (right) in Door environment. The latent policy $\bar{\pi}_{\bar{\theta}}$ is trained in the source environment with Panda robot while the action decoder $h_{\omega_2}$ is fine tuned with the Sawyer robot. Without additional interactions in the target environment with the Sawyer robot, the transferred policy achieved an average return of 736 while the expert return is 863.
Bibtex
Acknowledgements
We gratefully acknowledge support from ONR SAI N00014-18-1-2828. This webpage template was borrowed from SIREN.